摘要:随着改革开放的不断深入,居民家庭的收入水平和生活水平不断提高,对家庭资产配置有了更高质量的要求。资产配置涉及资产定价和投资优化组合等问题,已经成为数理统计、机器学习、行为金融等多学科的交叉研究热点。合理的资产配置策略不仅能够为投资者们带来可观的超额收益,还能促进资本市场健康发展和维护国家金融安全。大多数居民的投资策略基于历史投资经验、宏观市场的及时信息和个人的想法,难以随外界变化而灵活变通。人工智能、云计算、大数据等科学技术正重塑资产配置模型,运用相关技术可以提供更全面准确的信息分析,优化资产配置模型与策略,提升投资决策的效率与质量,从而在可控风险的条件下取得稳健收益,实现居民财富的保值增值目标。本文重点关注决策树和深度学习算法在资产定价问题上为居民资产配置提供的解决方案,并在中国A股市场的几个关键指数上验证了模型的有效性。本文的贡献如下:其一,基于LightGBM的决策树模型与传统多因子组合模型相比,具有可解释性强、数据质量要求低等特点,在沪深300和A500的指数成分股上运用纯多头策略实现了年化收益率约7%和2%的提升;其二,基于Transformer的深度学习模型与其他深度模型相比,通过自注意力机制可以挖掘更深的隐含关系具有更强的非线性拟合能力,在沪深300和A500的指数成分股上相比ALSTM(基于注意力的长短记忆网络)实现了年化收益率0.7%和1%的提升。相关算法的研究丰富了证券公司智能投顾平台的资产配置策略,为居民提供了多样化的财富管理方案。
1.引言
本世纪以来,我国居民财富积累速度加快,其中房地产占家庭财富的比例高达80%,大幅领先以股票、基金为代表的权益类金融资产占比。在财富管理市场,银行理财占比高达50%,远远高于基金、信托和保险资管等产品的比例。该现象与国际上成熟的财富管理市场截然相反。党的二十大报告中强调中国式现代化是全体人民共同富裕的现代化,而居民财富的保值增值是实现共同富裕的重要途径之一。随着近年来我国对房地产市场的科学调控以及银行存款利率跌破2%,居民将挤出更多存款向资本市场倾斜。
合理的资产配置策略不仅能够为投资者带来较为可观的超额收益,同时对于促进资本市场健康发展和维护金融安全具有重要现实意义。大多数居民的投资策略是基于历史投资经验、宏观市场的及时信息和个人的想法,难以随外界变化而灵活变通;此外投资标的急剧增加以及标的信息的大爆炸导致传统的资产配置策略面临着资产数量维度大和投资信息集维度高的挑战,因此构建适应当前时代投资需求的资产配置方法显得尤为必要。
人工智能、云计算、大数据等科学技术驱动着资产配置模型的转型和重塑。通过对海量数据的挖掘,为居民资产配置提供更全面、深入的信息基础;通过对风险承受能力和收益目标的平衡,为居民定制合理的风险控制方案;通过对市场动态的跟踪,帮助居民及时调整资产配置策略,避免因信息滞后而导致的决策失误。
面对金融市场非平稳和随机的本质,机器学习能够处理和分析非线性关系,通过过滤噪音和降低特征维度发现隐藏的模式和趋势,揭示传统方法难以捕捉的复杂数据结构,提高策略的灵活性和准确性。决策树模型相比传统的特征工程技术(例如主成分分析、奇异值分解和独立成分分析等)能够提供清晰的决策路径和规则,可解释性好;在处理输入变量的异常值和缺失值上不需要严格的标准化数据,具有较强的鲁棒性;在训练和推理的过程中会自动筛选特征的信息增益,有效避免无关或冗余特征的影响。本文在股票上利用LightGBM树模型对资产价格进行回归和分类的尝试,验证了机器学习算法的有效性,缓解了人工筛选因子的难度,提升了资产定价的效率。
在海量数据的背景下,深度学习技术从卷积神经网络 (CNN)、循环神经网络(RNN)、图神经网络 (GNN)到现在以ChatGPT为代表的大语言模型(LLM),通过堆叠更多的参数层可以拟合更复杂的环境变量。以Transformer为代表的自注意力机制,作为大语言模型的核心技术,无论是在处理多资产横截面收益分析的问题还是单资产时间序列预测的问题上都有很好的泛化性。本文在股票上利用Transformer编码器从时间和空间两个维度分析资产收益,通过自注意力机制捕获资产本身在时间上的动量效应以及资产相互间的价格传导机制,实现了更准确的价格预测,扩展了传统投研方法的边界。
综上,对于资产定价,本文探索了以LightGBM为代表的决策树模型和以Transformer为代表的深度神经网络在股票价格趋势预测上的非线性拟合能力。
2.相关工作
2.1资产定价
在不确定条件下资产未来风险与收益之间的权衡关系是资产定价(Asset Pricing)的核心问题。传统资产定价模型主要有资本资产定价模型(CAPM)[1]和套利定价理论(APT)[2]。
CAPM是基于风险资产期望收益均衡基础上的预测模型,它认为资产的预期收益率等于无风险利率加上风险溢价,而风险溢价取决于资产的系统性风险:
![]()
其中E(Ri)是资产i 的预期收益率,Rf是无风险利率,资产的贝塔系数βi衡量资产相对于市场组合的系统性风险,E(Rm)是市场组合的预期收益率。
APT认为资产的预期收益率取决于多个因素,而不仅仅是市场组合的收益率。它通过构建多因素模型来解释资产的收益:
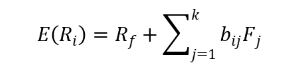
其中bij是资产i对第j个因素的敏感度,Fj是第j个因素的风险溢价,k是风险因素的数量。如果资产的定价不合理,就会出现套利机会,投资者会通过套利行为使资产价格回归合理水平。
Fama-French三因子模型[3]认为股票的收益率除了受市场风险因素影响外,还受到公司规模、账面市值比等因素的影响。套利定价理论为三因子模型的发展提供了理论基础,Fama-French三因子模型是在套利定价理论基础上的具体应用和拓展。Fama-French多因子模型还存在盈利水平风险、投资水平风险等其他因素影响股票的收益率。随着数据的丰富和计算能力的提升,大量的因子被挖掘出来,用于解释资产价格或投资组合的表现,就如同一个“动物园” 里有各种各样的因子——“Factor Zoo”。这些因子来源多样、数量众多且特性各异,主要分为市场因子、规模因子、价值因子、盈利因子、投资因子等。
2.2机器学习
金融数据和因子的几何式增长对传统资产定价和组合管理模型的参数估计、有效性都充满了挑战。随着深度学习的提出和硬件算力的提升,金融领域也正在迎接“大数据+深度模型”的时代。金融数据具有非线性、非平稳性和高噪音性三大性质,这对于传统统计学方法是苦难的,但机器学习不需要复杂的数据预处理,能够通过大量样本的训练保证模型的泛化能力。
其中集成学习算法将多个弱学习器通过各种投票机制构建成一个强学习器的模型,在图像识别、自然语言处理等领域都有广泛应用。目前集成算法分为Bagging(袋装法)和Boosting(提升法)两类。Bagging以随机森林为代表,通过对原始数据集进行有放回的随机抽样,得到多个不同的子数据集,然后分别在这些子数据集上训练多个弱学习器(通常是决策树),最后通过投票等方式将这些弱学习器的结果进行组合。Boosting以AdaBoost(Adaptive Boosting)、 GBDT(Gradient Boosting Decision Tree)为代表,是一种串行的集成方法,即依次训练多个弱学习器,每个弱学习器都是基于上一个弱学习器的错误进行调整和改进。通过不断地调整样本权重和学习器权重,使得后续的弱学习器更加关注那些被前一个弱学习器错误分类的样本,从而逐步提高整体模型的性能。微软开发的LightGBM[6]采用了一系列优化技术,在训练速度、内存占用和准确率等方面具有明显优势,广泛应用于信用风险评估、金融市场价格和趋势预测等任务。
端到端的深度学习是一种直接从原始输入数据到最终输出目标的方法,无需手工设计中间步骤或特征工程。它试图通过构建深度神经网络,让模型自动学习从输入到输出的映射关系。它无须专业人员深刻复杂的先验知识,取消了对数据和模型内部逻辑的复杂处理和设计。卷积神经网络(CNN)、长短期记忆网络(LSTM)[7]和Transformer[8]成为深度学习主流的模型架构,CNN 通过卷积层、池化层和全连接层等组合来提取二维空间数据的特征;LSTM由遗忘门、输入门和输出门组成,解决了传统 RNN(循环神经网络)在处理长序列时面临的梯度消失和梯度爆炸问题,用于处理序列数据;Transformer基于注意力机制,摒弃了传统的递归和卷积结构,可以高度并行化计算大大加快训练速度,无论是在长时间序列数据还是二维空间数据上都取得了非常好的效果。
3.研究方法
3.1 LightGBM
根据决策树输出结果的不同,决策树可以分为分类树和回归树两类。其核心逻辑是根据度量标准,从树根开始选择最优特征逐级分裂,递推生成一颗完整的决策树。业界大多使用信息增益(表示信息不确定性减少的程度,越大越好)、信息增益比(越大越好)、基尼系数(衡量集合的纯度,越小越好)作为分裂标准。CART(Classification and Regression Tree)决策树每次选择基尼系数最小的属性进行迭代,它既可以解决分类问题又可以解决回归问题。决策树在建立树时如果参数选择不合理(即树根或者枝干略有差池),树就可能会彻底长偏,产生过拟合的现象,导致泛化能力变弱,因此大多会采用剪枝、交叉验证等手段。除此之外,为了有效减少单决策树带来的问题,与决策树相关的组合(比如Bagging, Boosting等算法)也逐渐被引入进来,这些算法的精髓都是通过生成N棵树(N可能高达几百)最终形成一棵最适合的大树。如图3-1所示,Bagging技术类似多数投票机制,对于不同的分类器可以通过并行训练而获得,且每个分类器的权重相等;但Boosting则是在前面已训练获得的分类器基础上加以调整(更关心之前分类器分错的样本)而获得新的分类器,因此Boosting中的分类器权重并不相等,其权重值代表该分类器在上一轮迭代中的成功度。总的来说Boosting主要关注降低偏差,能基于泛化性能相对弱的学习器构建出很强的集成;Bagging主要关注降低方差,在不剪枝的决策树、神经网络等学习器上效用更为明显。GBDT(Gradient Boosting Decision Tree)是基于bagging的算法,通过构造一组弱的分类回归树CART,并把多颗决策树的结果累加起来作为最终的预测输出。所有弱分类器的结果相加等于预测值。每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差(预测值与真实值之间的误差)。LightGBM是GBDT的算法实现,引入了并行方案、基于梯度的单边检测、排他性特征捆绑等,提供一个快速高效、低内存占用、高准确度、支持并行和大规模数据处理的数据科学工具。在本研究中,将股票的多因子特征作为输入,股票未来几日的收益率作为标签,通过决策树拟合股票未来N天的收益率变化趋势。
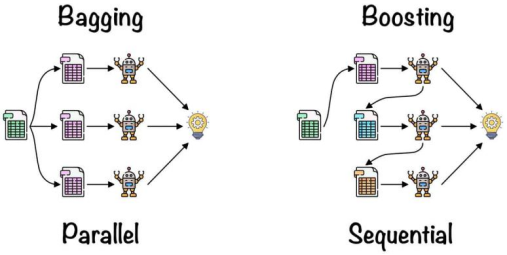
图3-1 集成算法Boosting和Bagging的区别
3.2 Transformer
自从BERT(一种基于Transformer架构的深度学习模型)和GPT模型取得重大成功之后,Transformer结构已经替代了循环神经网络(RNN)和卷积神经网络 (CNN),成为了当前NLP模型(自然语言处理模型)的标配。如图3-2所示,Transformer模型架构中的左半部分为编码器(Encoder),右半部分为解码器(Decoder)。
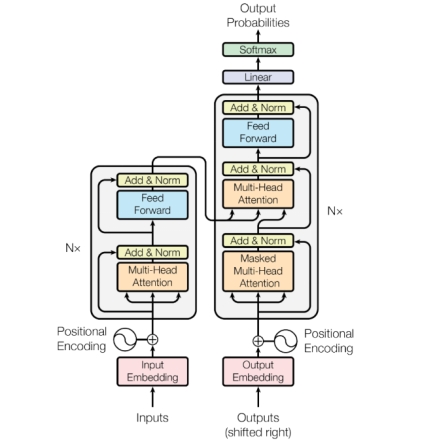
图3-2 Transformer架构
Encoder和Decoder是由Multi-Head Attention多头注意力层、Add&Norm残差正则化层、Feed Forward全连接层组合堆叠而成,其中Multi-Head Attention是多个Self-Attention自注意力组成。整个计算公式如下:
![]()
![]()
自注意力机制在计算的时候需要用到矩阵Q(查询)、K(键值)、V(值):
![]()
公式中在计算矩阵Q和K内积时,为了防止内积过大,因此除以dk的平方根。而多头注意力是由多个自注意力组合形成,通过将每个自注意机制的输出拼接在一起(Concat),然后传入一个线性层,得到最终的输出。多头注意力的输出和原始输入相加是一种残差连接,类似于ResNet中解决多层网络训练过拟合的问题,让网络只关注当前差异的部分。LayerNorm用于归一化单个数据样本中所有特征的均值和方差,有利于序列化样本以及批处理规模较小或动态的情况。全连接层包含两层,第一层的激活函数为ReLU,第二层不使用激活函数。在本文研究中,仅适用Transformer的编码器部分,对输入的股票多因子特征进行编码,经过堆叠多层的多头注意力和全连接层后将所有隐藏的因子特征求和作为输出,进行股票未来收益率的回归。
4.研究实验
4.1实验设置
数据集:为了验证资产配置的实证效果,我们对中国A股市场两个主要股票指数(CSI300和A500)的成分股进行了测试,期望达到指数增强。值得注意的是,中国A股市场不允许空头仓位,为了验证因子组合模型的有效性,在实验中假设A股允许空头。数据被分为训练集和测试集,如表4-1所述。由于缺少数据或者存在ST警告,一些公司实际会被剔除股票池。
表4-1 实验数据统计分析
Index | #Stocks | Training | Test |
CSI300 | 300 | 2014.01-2021.12 | 2022.01-2024.04 |
A500 | 500 | 2014.01-2021.12 | 2022.01-2024.04 |
基准模型:对于LightGBM和Transformer,这类直接预测股票价格然后根据未来涨跌幅进行横截面排序配置资产比例的模型,我们选取了等权因子组合模型(Eqw)、DNN、LSTM进行比较。
评估标准:我们利用六种评估指标来满足投资者的不同风险偏好,如下:(1)利润标准,包括年化收益率 (ARR)。(2) 风险标准,包括年化波动率 (AVol) 和最大回撤 (MDD)。(3) 风险利润标准,包括年化夏普比率 (ASR)、卡尔玛比率 (CR) 和索提诺比率 (SoR)。对于 AVol 和 MDD,较低的值是可取的;而对于 ARR、ASR、CR 和 SoR,较高的值是可取的。此外还引入了换手率衡量实际交易中的交易成本。
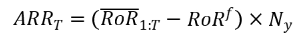
ARRT(Annualized Rate of Return)是一个持有周期的年化平均收益率,RoR 1:T是持有期的平均收益率,RoRf是无风险收益率,Ny是一年中持有周期的个数。
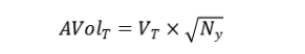
AVolT(Annualized Volatility)是年化平均波动率,反映了策略的风险水平。
![]()
MDDT(Maximum DrawDown)是衡量投资策略在最糟糕情况下的损失,ACi和ACj是在时间戳i和j下的累计资产净值。
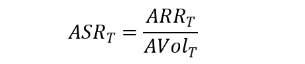
ASRT(Annualized Sharpe Ratio)是年化夏普率,基于年化波动率的风险调整收益。
TVRT(Turnover Ratio)是换手率,在T时期内的成交量和发行总股数的比值。
4.2实验结果
4.2.1 LightGBM
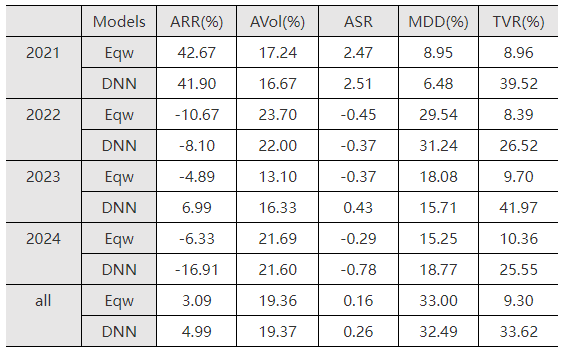
为了验证机器学习算法是否能够优化已有因子组合的资产配置,我们基于已有股票因子测试了LightGBM和多因子等权组合的效果。表4-2和表4-3分别展示了LightGBM和等权组合在沪深300和A500两个指数成分股纯多头(按照因子组合结果排序取前50%的股票支数)的资产配置条件下收益和风险的表现。
整体来看LightGBM相比等权组合,在年化收益率、年化夏普率、最大回撤指标上结果更好,在年化波动率和换手率指标上结果稍逊。这表明机器学习算法可以改进传统的资产配置结果,实现在风险可控条件下较高的收益。在2022、2023年市场低迷的情况下,LightGBM的资产组合能够减少损失;在2021年市场行情好的情况下,LightGBM也能够迅速捕捉热点抓住赚钱效应;在2024年市场波动剧烈的情况下,LightGBM的组合表现可能不尽如人意,因此我们可以将LightGBM和已有的因子组合模型相结合,形成一个多样化且鲁棒性强的组合配置策略。
表4-2 LightGBM和因子等权线性组合的沪深300成分股组合结果
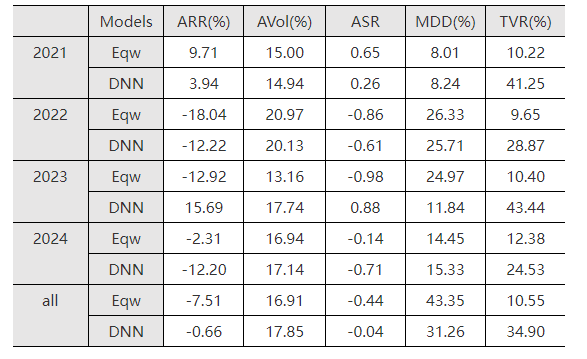
表4-3 LightGBM和因子等权线性组合的A500成分股组合结果
4.2.2 Transformer
为了激发深度学习模型的非线性拟合能力,我们尝试了对已有因子的组合配置采取多层感知机DNN、基于注意力的长短记忆神经网络ALSTM以及基于自注意力机制的Transformer三种深度学习算法,测试其在沪深300和A500上多头组合的结果。如表4-4所示,三个深度模型和等权组合相比,在年化收益率、年化波动率、年化夏普率和最大回撤指标上结果更有,但是换手率更高,这表明机器学习算法能够迅速捕捉市场热点进行调仓。图4-1和图4-2展示了三种深度学习模型在沪深300和A500成分股组合上的净值曲线,在2020-2023年左右,深度学习模型表现稳健回撤小,在2023-2024行情剧烈和横幅振荡的情况下表现优异,能够减少投资者的损失。
通过在指数上的实证研究,基于LightGBM和Transformer算法的资产配置策略在市场波动较大的时期,投资组合的平均年化波动率较传统资产投资有明显改善,同时年化收益率保持在相对稳定且具有竞争力的水平,实现了风险与收益的有效平衡。
表4-4 DNN、ALSTM、Transformer在沪深300和A500上的资产组合结果
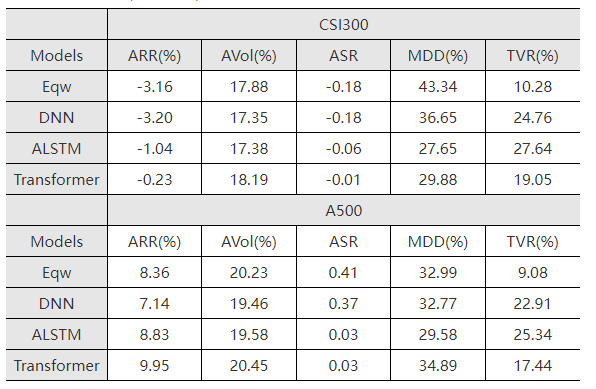
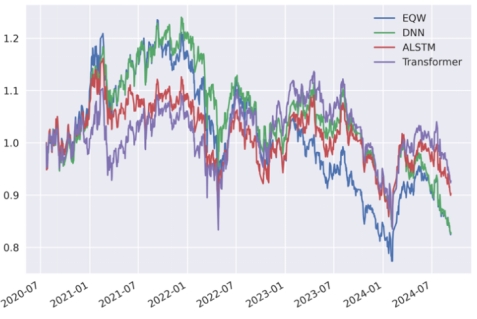
图4-1 不同深度学习模型在沪深300成分股组合上的累计净值
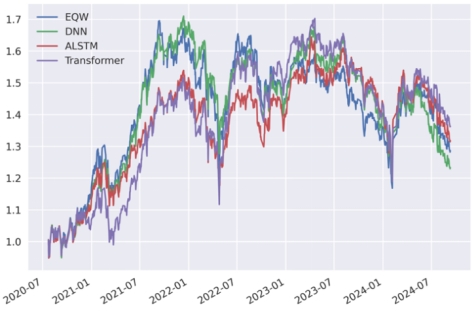
图4-2 不同深度学习模型在A500成分股组合上的累计净值
5.结论
本文在资产配置任务上,引入了各种机器学习和深度学习算法,并应用于中国A股市场。通过决策树模型验证了机器学习算法可以适应不同经济形势下的A股市场创造稳定的组合收益,相比手工构造因子组合提高了组合配置的效率;通过深度学习的Transformer模型应表明深度学习模型拥有更强的非线性拟合能力,可以构造出多样化的因子组合结果。这证实了人工智能在为居民提供更全面准确的市场信息、个性化定制的资产配置方案、提高投资效率等多方面的价值。同时,人工智能技术对证券公司而言,可以辅助客户行为分析,改善客户的个性化资产投资方案,提升公司服务水平帮助居民更好地实现财富管理目标,践行证券行业以人民为中心的理念。
参考文献
[1] Perold, A.F., 2004. The capital asset pricing model. Journal of economic perspectives, 18(3), pp.3-24.
[2] Huberman, G., 2005. Arbitrage pricing theory (No. 216). Staff Report.
[3] Sharma, R. and Mehta, K., 2013. Fama and French: Three factor model. SCMS Journal of Indian Management, 10(2), p.90.
[4] Markowitz, H., 1952. Modern portfolio theory. Journal of Finance, 7(11), pp.77-91.
[5] Cheung, W., 2010. The black–litterman model explained. Journal of Asset Management, 11, pp.229-243.
[6] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q. and Liu, T.Y., 2017. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
[7] Hochreiter, S., 1997. Long Short-term Memory. Neural Computation MIT-Press.
[8] Vaswani, A., 2017. Attention is all you need. Advances in Neural Information Processing Systems.
[9] Jiang, Z., Xu, D. and Liang, J., 2017. A deep reinforcement learning framework for the financial portfolio management problem. arXiv preprint arXiv:1706.10059.
[10] Wang, J., Zhang, Y., Tang, K., Wu, J. and Xiong, Z., 2019, July. Alphastock: A buying-winners-and-selling-losers investment strategy using interpretable deep reinforcement attention networks. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 1900-1908).
[11] Wang, Z., Huang, B., Tu, S., Zhang, K. and Xu, L., 2021, May. DeepTrader: a deep reinforcement learning approach for risk-return balanced portfolio management with market conditions Embedding. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 1, pp. 643-650).
[12] Niu, H., Li, S. and Li, J., 2022, October. MetaTrader: An reinforcement learning approach integrating diverse policies for portfolio optimization. In Proceedings of the 31st ACM international conference on information & knowledge management (pp. 1573-1583).
[13]李斌,屠雪永. 基于机器学习和资产特征的投资组合选择研究[J]. 系统工程理论与实践,2024,44(1):338-355. DOI:10.12011/SETP2023-1784.
[14]雷明明. 基于长期资产价格预测的投资组合算法[D].山东财经大学,2023.
[15]方毅,陈煜之,卫剑. 人工智能与中国股票市场——基于机器学习预测的投资组合量化研究[J]. 工业技术经济,2022,41(8):83-91. DOI:10.3969/j.issn.1004-910X.2022.08.011.
(作者:杨雨松,西南证券股份有限公司党委副书记、总经理,高级经济师;慕宗燊,西南证券股份有限公司博士后科研工作站研究人员)


